GraphQL API 漏洞是指由于 GraphQL 的设计特性(如灵活查询、自省机制、类型系统等)被不当使用或实现缺陷,导致的安全风险。这些漏洞可能被攻击者利用来窃取敏感数据、执行未授权操作、消耗服务器资源或绕过访问控制。
一、定义
GraphQL 是一种用于 API 的查询语言和运行时环境,由 Facebook 于 2012 年内部开发,2015 年开源,目前由 GraphQL 基金会(隶属于 Linux 基金会)维护。它的核心目标是让客户端能够精确获取所需数据,解决传统 REST API 中 “过度获取”“获取不足”“多端点请求” 等问题,同时通过强类型系统和自省能力提升 API 的可维护性和开发效率。
GraphQL 不与任何特定数据库或存储引擎绑定,而是由现有的代码和数据支持。
1.1 核心特性
GraphQL 的设计围绕 “灵活性” 和 “精确性” 展开,核心特性包括:
声明式查询(Declarative Queries)
客户端通过查询语句明确指定所需数据的结构,服务器仅返回请求的字段,避免 “过度获取”(如 REST 中一个接口返回冗余字段)。
例如,若客户端仅需博客的title和author,可直接查询:
query {
getBlogPost(id: 1) {
title
author
}
}
服务器返回的 JSON 结构与查询结构完全一致,无冗余字段。
强类型系统(Strong Typing)
所有数据(包括业务对象、参数、返回值)都有明确的类型定义(即 “Schema”),且查询必须符合类型规则,否则在执行前就会被拒绝。
例如,getBlogPost的参数id必须是Int!(非空整数),若传入字符串则直接报错(类似静态类型语言的编译时检查)。
单一端点(Single Endpoint)
不同于 REST 的 “多端点对应多资源”(如/posts、/users),GraphQL 通常通过单一端点(如/graphql)处理所有请求,客户端通过查询内容区分所需资源,简化 API 设计和维护。
自省能力(Introspection)
客户端可通过特殊查询获取服务器的 Schema 元数据(类型、字段、操作等),自动生成文档或验证查询合法性。这是 GraphQL “自描述” 的核心,极大降低了前后端协作成本。
支持复杂数据关联(Nested Queries)
一次查询可获取关联数据,无需像 REST 那样多次请求(如先查文章,再查作者)。例如,查询文章时同时获取作者信息:
query {
getBlogPost(id: 1) {
title
author { # 关联查询作者信息
name
avatar
}
}
}
二、核心概念
核心概念:Schema、类型系统与操作
GraphQL 的一切交互都基于Schema(数据模型定义),它是 API 的 “契约”,定义了可查询的类型、字段、操作及规则。
2.1 Schema:API 的 “蓝图”
Schema 是 GraphQL 的核心,包含两部分:
- 类型定义:描述数据的结构(如
BlogPost、User等对象类型); - 操作定义:指定客户端可执行的操作(查询、变更、订阅)。
例如,在文档中定义Schema 的BlogPost类型和query操作(getBlogPost、getAllBlogPosts),明确了 API 的能力边界。
2.2 类型系统:数据的 “骨架”
GraphQL 的类型系统是强类型的,所有数据必须符合预定义的类型规则。主要类型包括:
-
标量类型(Scalars):最基础的类型,不可再分,用于表示原子数据。
- 内置标量:
Int(32 位整数)、Float(双精度浮点数)、String(UTF-8 字符串)、Boolean(布尔值)、ID(唯一标识符,序列化后同String,但语义上表示唯一标识)。 - 自定义标量:可根据业务需求定义,例如可在文档中定义
Timestamp(表示时间戳,需服务器实现序列化 / 反序列化逻辑)。
- 内置标量:
-
对象类型(Object Types):由多个字段组成的复合类型,对应业务实体(如
BlogPost、User)。每个字段有名称、类型和可选参数。例如:type BlogPost { id: Int! # 非空整数(!表示非空) title: String! # 非空字符串 paragraphs: [String!]! # 非空列表,元素为非空字符串 isPrivate: Boolean! postPassword: String # 可空字符串(无!) } -
包装类型(Wrappers):用于修饰其他类型,表达 “列表” 或 “非空” 约束:
NON_NULL:用!表示,修饰的类型不可为null(如Int!表示必须返回整数,不能为null)。LIST:用[]表示,修饰的类型为列表(如[String]表示字符串列表,[String!]!表示非空列表且元素不可为null)。
-
接口(Interfaces):抽象类型,定义多个对象类型的共同字段,类似面向对象中的接口。例如:
interface Publication { id: Int! title: String! date: Timestamp! } type BlogPost implements Publication { ... } # 实现接口 type Article implements Publication { ... } # 实现接口 -
联合类型(Unions):表示 “多个类型中的一种”,无共同字段,用于返回多种可能的类型。例如:
union SearchResult = BlogPost | User | Comment query Search($keyword: String) { search(keyword: $keyword) { # 返回值可能是BlogPost、User或Comment ... on BlogPost { title } ... on User { name } } } -
枚举类型(Enums):限定值只能是预定义的枚举项,用于约束取值范围。例如:
enum PostStatus { DRAFT PUBLISHED ARCHIVED } type BlogPost { status: PostStatus! # 只能是DRAFT、PUBLISHED或ARCHIVED }
2.3 操作类型:客户端与服务器的交互方式
Schema 定义了三种操作类型,客户端通过这些操作与服务器交互:
-
查询(Query):用于获取数据,是只读操作(类似 REST 的 GET)。查询可并行执行,无副作用。例如可在文档query
类型中定义getBlogPost(单篇博客)和getAllBlogPosts`(所有博客)。 -
变更(Mutation):用于修改数据(创建、更新、删除),有副作用,且按顺序执行(避免并发问题)。例如:
type Mutation { createBlogPost(title: String!, content: String!): BlogPost! # 创建博客 updateBlogPost(id: Int!, title: String): BlogPost! # 更新博客标题 } -
订阅(Subscription):用于实时获取数据更新,基于 WebSocket 等持久连接,服务器在数据变化时主动推送。例如:
type Subscription { newBlogPost: BlogPost! # 当新博客发布时推送 }
三、查询语法
GraphQL 的查询操作(Query)是用于获取数据的只读操作,GraphQL 查询语法设计简洁灵活,支持字段选择、参数、片段、变量、指令等特性,确保客户端能精确获取所需数据。
3.1 基本结构
GraphQL 查询的核心是 “选择字段”,客户端通过声明式语法指定需要的字段,服务器返回的 JSON 结构与查询结构完全一致。其基本格式如下:
# 基础查询结构
query [查询名称] {
操作字段(参数) {
子字段1
子字段2
...嵌套字段 {
嵌套子字段
}
}
}
- 查询名称:可选,用于标识查询(尤其在多查询场景中区分),无名称的查询称为 “匿名查询”。
- 操作字段:对应 Schema 中
query类型定义的字段(如getBlogPost、getAllBlogPosts),是获取数据的入口。 - 参数:可选,用于过滤或指定数据(如
id: 1),需符合 Schema 中定义的类型。 - 字段 / 嵌套字段:客户端需要的具体数据字段,支持多层嵌套(如查询博客时同时获取作者信息)。
3.2 基础查询:字段选择
查询的核心是 “选择字段”,客户端指定需要的字段,服务器返回对应值。例如:
query {
getAllBlogPosts { # 调用查询操作
id
title
author
date
}
}
返回的结果结果与查询的一致:
{
"data": {
"getAllBlogPosts": [
{ "id": 1, "title": "GraphQL入门", "author": "Alice", "date": "2025-01-01" },
{ "id": 2, "title": "REST vs GraphQL", "author": "Bob", "date": "2025-01-02" }
]
}
}
3.3 参数:过滤与筛选
查询操作可接受参数,用于筛选数据。参数需在 Schema 中定义类型(如getBlogPost(id: Int!)中的id)。例如:
query {
getBlogPost(id: 1) { # 传入id参数,获取单篇博客
title
paragraphs
}
}
3.4 片段(Fragments):复用查询逻辑
片段是可复用的字段集合,用于简化重复的查询结构(类似代码中的函数)。例如可在文档查询中定义FullType片段,复用了__Type的字段:
fragment BlogPostFields on BlogPost { # 定义片段,仅在BlogPost类型上使用
id
title
author
}
query {
post1: getBlogPost(id: 1) { ...BlogPostFields } # 复用片段
post2: getBlogPost(id: 2) { ...BlogPostFields }
}
3.5 变量:动态传入参数
为避免硬编码参数(尤其在用户输入场景),可使用变量动态传递值。变量需声明类型,并在查询中用$引用:
query GetBlogPost($postId: Int!) { # 声明变量$postId,类型为非空Int
getBlogPost(id: $postId) {
title
}
}
请求时传入变量:
{
"query": "query GetBlogByVariable($postId: Int!) { getBlogPost(id: $postId) { title author } }",
"variables": { "postId": 1 }
}
3.6 指令(Directives):动态控制查询行为
指令用于在查询执行时动态调整字段的包含 / 排除,常见内置指令包括:
@include(if: Boolean!):当if为true时包含字段;@skip(if: Boolean!):当if为true时排除字段;@deprecated(reason: String):标记字段为废弃(在 Schema 中定义)。
例如,根据showSummary变量决定是否返回摘要:
query GetBlogPost($postId: Int!, $showSummary: Boolean!) {
getBlogPost(id: $postId) {
title
summary @include(if: $showSummary) # 条件性包含summary
}
}
3.7 嵌套查询:一次性获取关联数据
GraphQL 支持多层嵌套查询,可在一次请求中获取关联数据(如博客→作者→作者的其他文章),无需像 REST 那样多次请求不同端点。
例如,查询博客时同时获取作者的基本信息:
query {
getBlogPost(id: 1) {
title
author { # 嵌套查询作者信息(关联数据)
name
avatarUrl # 作者头像
publishedPosts { # 作者发布的其他文章(更深层嵌套)
id
title
}
}
}
}
返回结果包含嵌套的关联数据:
{
"data": {
"getBlogPost": {
"title": "GraphQL入门指南",
"author": {
"name": "Alice",
"avatarUrl": "/avatars/alice.jpg",
"publishedPosts": [
{ "id": 1, "title": "GraphQL入门指南" },
{ "id": 3, "title": "GraphQL最佳实践" }
]
}
}
}
}
3.8 别名(Aliases):同一操作的多次调用
当需要多次调用同一操作字段(如同时查询两篇不同的博客),可通过别名区分结果,避免字段名冲突。
例如,同时查询 ID 为 1 和 2 的博客:
query {
# 给getBlogPost(id:1)起别名post1
post1: getBlogPost(id: 1) {
title
}
# 给getBlogPost(id:2)起别名post2
post2: getBlogPost(id: 2) {
title
}
}
返回结果通过别名区分:
{
"data": {
"post1": { "title": "GraphQL入门指南" },
"post2": { "title": "REST与GraphQL对比" }
}
}
3.9 查询的验证与执行机制
GraphQL 服务器在返回数据前,会对查询进行严格验证和解析,确保其合法性和正确性。
3.9.1 验证阶段(Validation)
服务器首先验证查询是否符合 Schema 规则,主要检查:
- 语法正确性:如括号匹配、字段名拼写等;
- 类型匹配:字段是否属于对应类型(如
getBlogPost的返回值是否包含请求的字段); - 参数合法性:参数类型是否与 Schema 定义一致(如
id是否为Int); - 非空约束:是否为非空字段提供了值(如
Int!参数不能为null)。
若验证失败,服务器返回errors字段,不执行查询。例如,请求不存在的字段invalidField:
{
"errors": [
{
"message": "Cannot query field 'invalidField' on type 'BlogPost'.",
"locations": [{ "line": 3, "column": 5 }]
}
],
"data": null
}
3.9.2 执行阶段(Execution)
验证通过后,服务器按以下步骤执行查询:
- 解析查询为 AST:将查询字符串转换为抽象语法树(AST),便于程序处理;
- 执行 Resolver 函数:对每个字段,调用对应的 “解析函数”(Resolver)获取数据。Resolver 是连接 GraphQL 与数据源(数据库、API、缓存等)的桥梁,例如
getBlogPost的 Resolver 可能从数据库查询 ID 为 1 的博客; - 处理嵌套字段:若字段是对象类型(如
author),递归执行其 Resolver,直到所有字段处理完成; - 组装结果:按查询结构组装所有字段的返回值,生成
data字段返回。
3.10 查询的响应格式
GraphQL 查询的响应是 JSON 对象,包含两个顶级字段:
data:查询成功时,返回与查询结构一致的结果;查询部分成功时,返回成功部分的结果(失败字段为null);errors:查询失败时,返回错误数组(包含错误信息、位置等),仅在验证或执行出错时出现。
示例:部分成功的查询(post1成功,post2因 ID 不存在失败):
{
"data": {
"post1": { "title": "GraphQL入门指南" },
"post2": null # 失败的字段为null
},
"errors": [
{
"message": "Blog post with id 999 not found",
"locations": [{ "line": 5, "column": 3 }],
"path": ["post2"] # 指示错误发生的字段路径
}
]
}
四、工作流程
GraphQL 的交互流程可分为 “客户端发送查询”“服务器处理查询”“返回响应” 三个阶段,具体如下:
- 客户端构造查询:根据需求编写查询语句(含字段、参数、变量等),通过 HTTP POST 发送到 GraphQL 端点(如
/graphql)。 - 服务器验证查询:
- 语法验证:检查查询是否符合 GraphQL 语法规则(如括号匹配、字段存在);
- 类型验证:根据 Schema 检查字段类型、参数类型是否匹配(如
id是否为Int!); - 若验证失败,返回错误信息(如 “字段
invalidField不存在于BlogPost类型”)。
- 服务器执行查询:
- 解析查询:将查询转换为抽象语法树(AST);
- 执行 resolver:针对每个字段,调用对应的 “解析函数”(resolver)获取数据(resolver 可从数据库、API、缓存等数据源获取数据);
- 处理嵌套字段:若字段是对象类型(如
author),递归执行其 resolver。
- 返回响应:将执行结果按查询结构组装为 JSON,包含
data(成功结果)和errors(错误信息,若有)。
示例 AST(简化版):
Query
└─ posts(first:10, after:"cursor123")
├─ id
├─ title
└─ author
├─ id
└─ name
五、变更语法
GraphQL 的变更(Mutation)是用于修改数据(创建、更新、删除)的操作,与查询(Query)的 “只读” 特性不同,它会产生副作用(如数据变更),且执行时按顺序处理(避免并发冲突)。其语法设计与查询类似,但有明确的关键字和执行规则。
5.1 基本结构
Mutation 的核心是通过mutation关键字声明操作,指定需要修改的数据(参数)和修改后返回的结果(字段)。基本格式如下:
mutation [变更名称]($变量名: 类型!) {
变更操作字段(参数: $变量名) {
返回字段1
返回字段2
... # 通常返回修改后的数据,用于客户端同步状态
}
}
- mutation关键字:区分变更操作与查询操作(必须显式声明)。
- 变更名称:可选,用于标识变更(便于调试和日志)。
- 变更操作字段:对应 Schema 中
Mutation类型定义的字段(如createBlogPost、updateBlogPost),是修改数据的入口。 - 参数:修改数据所需的输入(如创建博客的
title、content),支持基础类型或复杂输入类型。 - 返回字段:变更执行后,服务器返回的字段(通常是修改后的完整数据,便于客户端更新本地状态)。
5.2 基础变更:创建数据
创建一篇博客,并返回创建后的id、title和date(确认创建成功)。
Schema 定义(服务器端):
type Mutation {
# 创建博客:参数为标题(非空字符串)、内容(非空字符串);返回BlogPost类型
createBlogPost(title: String!, content: String!): BlogPost!
}
type BlogPost {
id: Int!
title: String!
content: String!
date: Timestamp!
author: String!
}
变更请求(客户端):
# 命名变更CreateNewBlog,声明变量$title和$content
mutation CreateNewBlog($title: String!, $content: String!) {
# 调用createBlogPost,传入参数
createBlogPost(title: $title, content: $content) {
# 返回创建后的字段(用于客户端确认)
id
title
date
}
}
变量传入:
{
"variables": {
"title": "GraphQL Mutation入门",
"content": "这是一篇关于Mutation语法的博客..."
}
}
响应结果:
{
"data": {
"createBlogPost": {
"id": 3,
"title": "GraphQL Mutation入门",
"date": "2023-10-01T12:00:00Z"
}
}
}
5.3 复杂参数:使用输入类型(Input Type)
当变更需要传递复杂参数(如包含多个字段的对象)时,GraphQL 通过输入类型(Input Type)简化参数传递。输入类型用input关键字定义,类似对象类型但仅用于参数传递。
Schema 定义(输入类型):
# 定义输入类型:更新博客的参数
input UpdateBlogInput {
title: String # 可选:标题(可空,不更新则不传)
content: String # 可选:内容
isPrivate: Boolean # 可选:是否设为私密
}
type Mutation {
# 更新博客:参数为id(非空)和输入类型input
updateBlogPost(id: Int!, input: UpdateBlogInput!): BlogPost!
}
变更请求(更新博客标题和私密状态):
mutation UpdateBlog($id: Int!, $input: UpdateBlogInput!) {
updateBlogPost(id: $id, input: $input) {
id
title
isPrivate # 返回更新后的私密状态
}
}
变量传入:
{
"variables": {
"id": 3,
"input": {
"title": "GraphQL Mutation进阶", # 仅更新标题
"isPrivate": true # 设为私密
}
}
}
响应结果:
{
"data": {
"updateBlogPost": {
"id": 3,
"title": "GraphQL Mutation进阶",
"isPrivate": true
}
}
}
5.4 多变更操作:批量执行
一个 Mutation 请求可包含多个变更操作,服务器按顺序执行(不同于 Query 的并行执行),确保执行顺序可控(如先创建作者,再创建其博客)。
示例:先创建作者,再创建该作者的博客:
mutation CreateAuthorAndBlog($authorName: String!, $blogTitle: String!) {
# 第一步:创建作者
newAuthor: createAuthor(name: $authorName) {
id
name
}
# 第二步:创建博客(关联第一步的作者ID)
newBlog: createBlogPost(
title: $blogTitle,
content: "新博客内容",
authorId: $newAuthor.id # 引用前一个操作的返回结果
) {
id
title
author { name }
}
}
注意:
- 多变更需按书写顺序执行(先
createAuthor,后createBlogPost); - 可通过别名(
newAuthor、newBlog)区分结果,并引用前一个操作的返回值($newAuthor.id)。
5.5 删除操作:返回删除结果
删除操作通常返回被删除的数据 ID 或状态,确认删除成功。
Schema 定义:
type Mutation {
deleteBlogPost(id: Int!): DeleteResult!
}
type DeleteResult {
success: Boolean! # 是否删除成功
deletedId: Int! # 被删除的ID
message: String # 提示信息
}
变更请求:
mutation DeleteBlog($id: Int!) {
deleteBlogPost(id: $id) {
success
deletedId
}
}
响应结果:
{
"data": {
"deleteBlogPost": {
"success": true,
"deletedId": 3
}
}
}
5.6 与 Query 的关键区别
| 特性 | Query(查询) | Mutation(变更) |
|---|---|---|
| 作用 | 获取数据(只读) | 修改数据(有副作用) |
| 执行顺序 | 并行执行(无依赖) | 按顺序执行(确保变更顺序) |
| 关键字 | 可选(可省略query直接写查询) |
必须显式声明mutation关键字 |
| 返回值用途 | 直接展示数据 | 通常返回修改后的数据,用于客户端同步状态 |
Mutation 语法其核心特点是按顺序执行和处理副作用,适用于创建、更新、删除等数据修改场景。与 Query 相比,Mutation 更强调操作的顺序性和权限控制,确保数据修改的安全性和一致性。
六、与 REST API 的对比
| 特性 | REST API | GraphQL |
|---|---|---|
| 端点设计 | 多端点(如/posts、/users) |
单一端点(如/graphql) |
| 数据获取 | 固定结构,可能过度 / 不足获取 | 客户端按需请求,精确获取 |
| 关联数据获取 | 多次请求(如先查/posts再查/users) |
一次查询获取所有关联数据 |
| 版本管理 | 需维护多版本(如/v1/posts、/v2/posts) |
无需版本,通过字段增删兼容 |
| 文档生成 | 依赖外部工具(如 Swagger) | 内置自省能力,自动生成文档 |
| 缓存机制 | 基于 URL 和 HTTP 方法,简单直接 | 需客户端实现(如 Apollo Client) |
七、常见漏洞类型
结合 GraphQL 的技术特性和实际场景,常见的漏洞类型及原理如下:
7.1 自省机制滥用:信息泄露风险
GraphQL 的自省机制(如文档 2 中的IntrospectionQuery)允许客户端查询 Schema 元数据(类型、字段、参数等),这是其 “自描述” 的核心优势,但也可能成为信息泄露的入口。
- 漏洞原理:若生产环境未禁用自省,攻击者可通过自省查询获取完整的 Schema 结构,包括:
- 敏感字段(如
userPassword、creditCard等本应隐藏的字段); - 未公开的操作(如
adminQuery等仅管理员可访问的接口); - 数据关联关系(如
user与order的关联,帮助攻击者构造定向查询)。
- 敏感字段(如
- 示例:文档 1 的响应中包含
BlogPost的postPassword字段,若生产环境允许自省,攻击者可通过自省发现该字段存在,进而尝试查询私密博客的密码。 - 风险:攻击者可基于泄露的 Schema 精准构造恶意查询,大幅降低攻击难度。
7.2 查询复杂度攻击:服务器资源耗尽(DoS)
GraphQL 允许客户端构造嵌套查询(如查询博客→作者→作者的所有文章→每篇文章的评论……),若未限制查询深度或复杂度,可能导致服务器资源被耗尽。
-
漏洞原理:
- 复杂查询(深层嵌套、大量字段、重复调用)会触发大量 Resolver 函数执行(如多次数据库查询、外部 API 调用),消耗 CPU、内存或数据库连接;
- 攻击者可构造 “递归查询”(如利用自关联字段
user.friends.friends.friends...),形成指数级资源消耗。
-
示例:针对
getBlogPost的嵌套查询:query MaliciousQuery { getBlogPost(id: 1) { author { posts { author { posts { author { ... } # 无限嵌套,触发大量数据库查询 } } } } } } -
风险:服务器响应延迟、崩溃或拒绝服务,影响正常用户访问。
7.3 访问控制绕过:未授权数据访问
GraphQL 的字段级权限控制依赖 Resolver 函数实现(即每个字段的访问权限需单独验证),若实现不当,可能导致未授权访问。
- 漏洞原理:
- 开发者可能仅验证顶层操作(如
getBlogPost)的权限,而忽略嵌套字段的权限(如author字段包含用户手机号等敏感信息); - 私密字段(如
isPrivate: true的博客)未在 Resolver 中校验密码或权限,导致攻击者直接查询。
- 开发者可能仅验证顶层操作(如
- 示例:文档 1 中
BlogPost有isPrivate字段(标记是否为私密文章)和postPassword字段(访问密码)。若 Resolver 未验证:- 攻击者可直接查询
isPrivate: true的博客内容(无需密码); - 即使
postPassword字段存在,若未限制查询权限,攻击者可直接获取密码明文。
- 攻击者可直接查询
- 风险:敏感数据(如用户信息、私密内容、内部数据)被未授权访问。
7.4 注入攻击:通过参数注入恶意代码
尽管 GraphQL 有强类型系统(参数类型需匹配 Schema 定义),但 Resolver 函数若未正确处理输入参数,可能导致注入攻击。
-
漏洞原理:
- 若 Resolver 将 GraphQL 参数直接拼接为数据库查询(如 SQL、NoSQL),攻击者可构造特殊参数触发注入;
- 类型系统仅验证参数 “类型”(如
Int、String),不验证 “内容合法性”(如 SQL 关键字)。
-
示例:假设
getBlogPost的 Resolver 直接拼接id参数为 SQL 查询:-- 危险的Resolver实现(伪代码) sql = "SELECT * FROM posts WHERE id = " + $id; # $id为GraphQL参数攻击者可传入
id: "1 OR 1=1"(若 Schema 中id错误定义为String类型),触发 SQL 注入,获取所有博客数据。 -
风险:数据库信息泄露、数据篡改或服务器受控。
7.5 批量数据泄露:过度暴露数据
GraphQL 的LIST类型和批量查询操作(如文档 1 中的getAllBlogPosts)若未限制返回数量,可能导致批量数据泄露。
- 漏洞原理:
- 批量查询操作(如
getAllUsers、getAllOrders)若未分页或权限校验,攻击者可一次获取所有数据; - 结合过滤参数(如
where: { role: "admin" }),攻击者可定向批量获取敏感数据(如所有管理员信息)。
- 批量查询操作(如
- 示例:文档 1 中的
getAllBlogPosts返回所有博客,若未限制且包含postPassword字段,攻击者可一次获取所有私密博客的密码。 - 风险:大量用户数据、商业信息或内部数据被批量窃取,违反数据保护法规(如 GDPR)。
7.6 错误信息泄露:暴露系统细节
GraphQL 的错误响应若包含详细信息(如堆栈跟踪、数据库路径、Schema 结构),可能被攻击者利用来分析系统弱点。
- 漏洞原理:
- 开发环境的错误提示(如 “数据库连接失败:user ‘admin’@‘localhost’”)被带入生产环境;
- 验证失败时返回具体原因(如 “用户 ID=123 不存在”,帮助攻击者枚举有效 ID)。
- 示例:查询不存在的字段时,错误信息返回:
{
"errors": [
{
"message": "Field 'secretField' does not exist on type 'User'. Did you mean 'password'?",
"locations": [{ "line": 3, "column": 5 }]
}
]
}
攻击者可通过此类信息猜测敏感字段名称(如password)。
- 风险:攻击者获取系统实现细节,为进一步攻击(如社会工程学、定向注入)提供线索。
八、自省能力
GraphQL 的自省能力(Introspection) 是其核心特性之一,指 GraphQL 服务允许客户端通过特殊查询获取自身数据模型(Schema)的元信息(如类型定义、字段结构、操作规则等)的能力。这种 “自我描述” 的特性让 GraphQL API 具备动态可探索性,无需依赖外部文档即可让客户端理解其功能边界。
8.1 自省能力的核心原理
GraphQL 的自省机制基于一套预定义的元类型(Meta Types) 实现,这些元类型以双下划线__为前缀(如__schema、__type),专门用于描述 Schema 本身的结构。
- 客户端通过发送包含这些元类型的查询(如
query { __schema { ... } }),向服务器请求 Schema 信息; - 服务器识别元类型查询后,返回包含类型定义、字段关系、操作规则等的元数据;
- 客户端(或工具)解析这些元数据,即可动态生成文档、验证查询合法性或生成代码。
8.2 核心元类型
自省的核心是一组元类型,它们构成了描述 Schema 的 “元数据语言”。
8.2.1 __Schema:整个 Schema 的根元类型
__Schema是自省的入口,包含整个 GraphQL 服务的顶层元信息,主要字段:
queryType:查询操作的根类型(如query类型,包含getBlogPost等查询字段);mutationType/subscriptionType:突变、订阅操作的根类型(若服务支持);types:服务中所有类型的列表(包括业务类型如BlogPost、标量类型如Int、元类型本身如__Type);directives:服务支持的指令(如@include、@deprecated)。
8.2.2 __Type:描述 “类型” 的元类型
__Type是最核心的元类型,用于描述服务中所有类型的细节(无论业务类型、标量还是元类型)。主要字段:
kind:类型的种类(枚举__TypeKind,如OBJECT、SCALAR、LIST等);name:类型名称(如BlogPost、Int、__Schema);fields:若类型是OBJECT或INTERFACE,则包含其字段列表(每个字段由__Field描述);ofType:若类型是LIST或NON_NULL(包装类型),则指向其内部类型(如[String!]!的ofType是String);enumValues:若类型是ENUM,则包含枚举值列表;inputFields:若类型是INPUT_OBJECT(输入类型),则包含输入字段列表。
8.2.3 __Field:描述对象类型的 “字段”
__Field用于描述OBJECT或INTERFACE类型中的具体字段(如BlogPost的title字段),主要字段:
name:字段名称(如title、id);description:字段的描述信息(可选,用于生成文档);args:字段的参数列表(每个参数由__InputValue描述);type:字段的返回类型(由__Type描述)。
8.2.4 __InputValue:描述参数或输入字段
__InputValue用于描述字段的参数(如getBlogPost(id: Int!)中的id)或输入类型的字段(如UpdateBlogInput的title),主要字段:
name:参数 / 输入字段的名称;description:描述信息;type:参数 / 输入字段的类型(由__Type描述);defaultValue:默认值(若有)。
8.2.5 __TypeKind:类型种类的枚举
__TypeKind是枚举类型,定义了所有可能的类型种类,决定了__Type的行为:
- 基础类型:
SCALAR(标量)、OBJECT(对象)、ENUM(枚举)、INTERFACE(接口)、UNION(联合)、INPUT_OBJECT(输入对象); - 包装类型:
LIST(列表)、NON_NULL(非空)。
8.3 标准自省查询
GraphQL 规范定义了一个标准的自省查询(IntrospectionQuery),用于获取完整的 Schema 元数据。以下是简化版示例(完整版本包含所有元类型的细节):
query IntrospectionQuery {
__schema {
# 获取查询、突变、订阅的根类型
queryType { name }
mutationType { name }
subscriptionType { name }
# 获取所有类型的详细信息
types {
...FullType
}
# 获取所有指令
directives {
name
description
locations
args { ...InputValue }
}
}
}
# 片段:展开类型的完整信息
fragment FullType on __Type {
kind
name
description
# 若为对象/接口类型,获取字段
fields(includeDeprecated: true) {
name
description
args { ...InputValue }
type { ...TypeRef }
isDeprecated
deprecationReason
}
# 若为枚举类型,获取枚举值
enumValues(includeDeprecated: true) {
name
description
isDeprecated
deprecationReason
}
# 若为输入对象类型,获取输入字段
inputFields { ...InputValue }
# 若为接口/联合类型,获取实现/包含的类型
interfaces { ...TypeRef }
possibleTypes { ...TypeRef }
}
# 片段:展开参数/输入字段的信息
fragment InputValue on __InputValue {
name
description
type { ...TypeRef }
defaultValue
}
# 片段:展开类型引用(处理嵌套类型如列表、非空)
fragment TypeRef on __Type {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType { ...TypeRef }
}
}
}
查询结果:返回一个包含完整 Schema 的 JSON,包含所有类型、字段、指令的元信息(如文档 1 的响应就是对这个查询的返回)。
8.4 实用自省查询场景
除了完整 Schema,还可针对特定需求编写自省查询:
8.4.1 查询特定类型的所有字段
若已知类型名(如BlogPost),直接查询其字段:
query GetBlogPostFields {
__type(name: "BlogPost") {
name
fields {
name # 字段名(如id、title、isPrivate)
type { name } # 字段类型(如Int、String、Boolean)
}
}
}
8.4.2 查询所有业务对象类型
筛选kind: "OBJECT"的类型(排除标量、元类型等):
query GetAllObjectTypes {
__schema {
types {
name
kind
}
}
}
8.4.3 查询所有可用的查询操作
获取query类型的所有字段(即客户端可执行的查询):
query GetAllQueries {
__schema {
queryType {
name
fields {
name # 查询操作名(如getBlogPost、getAllBlogPosts)
args { name type { name } } # 操作的参数
}
}
}
}
九、防护措施
针对上述风险,规避 GraphQL API 漏洞,需从实现、配置和流程上综合防护:
限制自省机制:生产环境禁用自省(如 Apollo Server 设置introspection: false),仅允许开发 / 测试环境使用。
控制查询复杂度:
- 限制查询深度(如最多 5 层嵌套);
- 计算查询复杂度(如每个字段计 1 分,列表计额外分数),拒绝超过阈值的查询(工具如
graphql-cost-analysis)。
严格权限控制:
- 实现字段级权限校验(每个 Resolver 函数中检查用户权限);
- 对私密字段(如
postPassword)单独验证访问权限(如密码校验、角色校验)。
输入验证与过滤:
- 对所有参数进行合法性校验(如
id范围、字符串长度); - Resolver 中使用参数化查询(避免直接拼接 SQL/NoSQL)。
限制批量数据返回:
- 批量操作强制分页(如
page: Int!、pageSize: Int!),并限制pageSize最大值; - 敏感批量查询需额外权限校验。
规范错误响应:
- 生产环境返回通用错误信息(如 “请求失败,请稍后重试”),隐藏具体细节;
- 日志中记录详细错误,但不暴露给客户端。
十、常见的GraphQL 端点后缀
10.1 常见路径
- /graphql
- /gql
- graphql/v1
- graphql/v2
- /api/graphql
- /internal/graphql
- /graphql.php
- /graphql.json
- /graphql.aspx
- /
- /query
- /api
10.2 测试建议
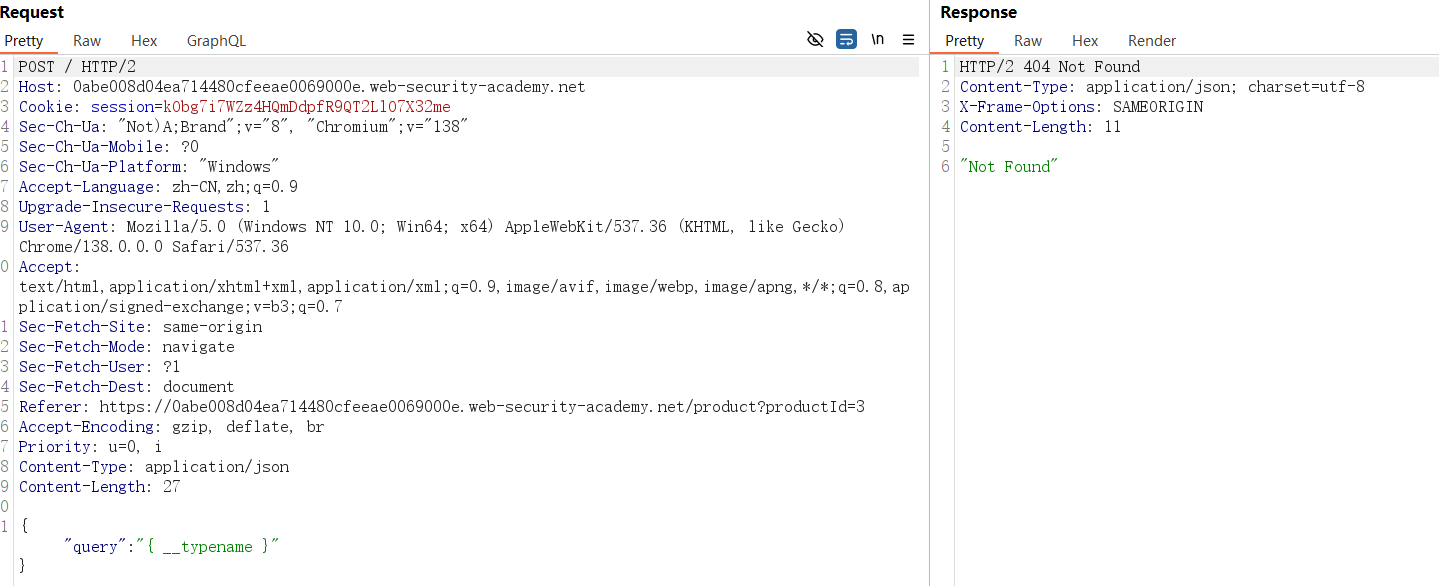
对上述路径发送POST 请求,Content-Type 设为application/json,请求体包含简单的 GraphQL 查询(如自省查询片段):
{"query": "{ __typename }"}
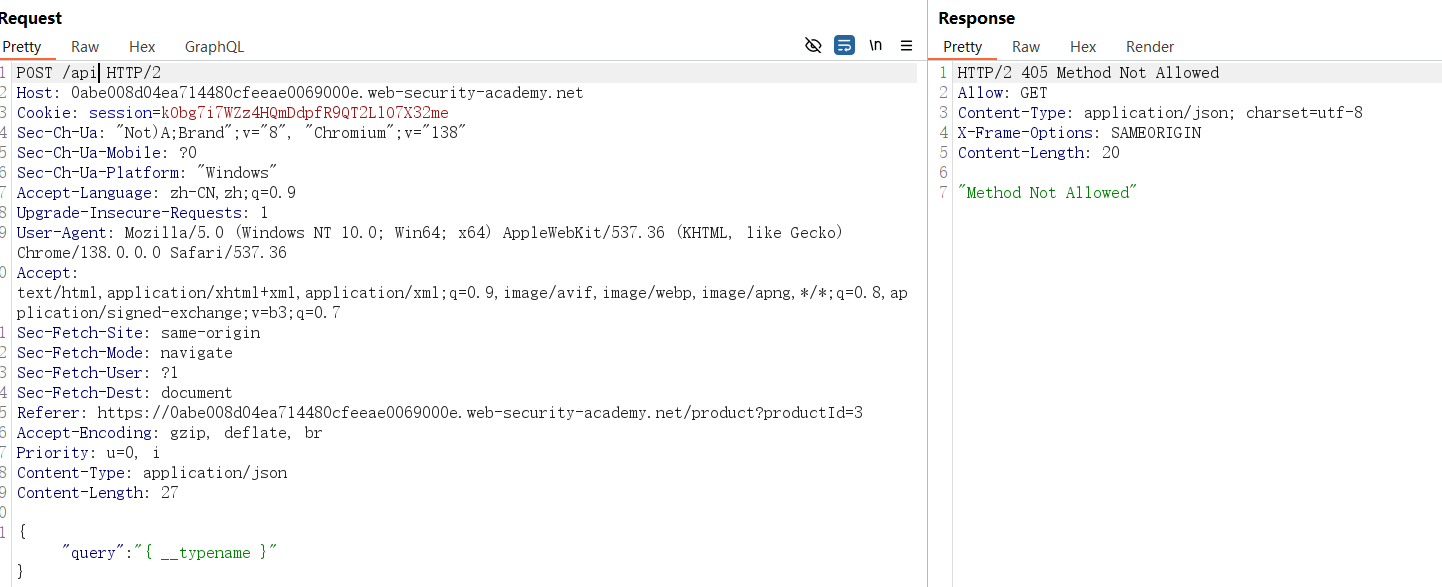
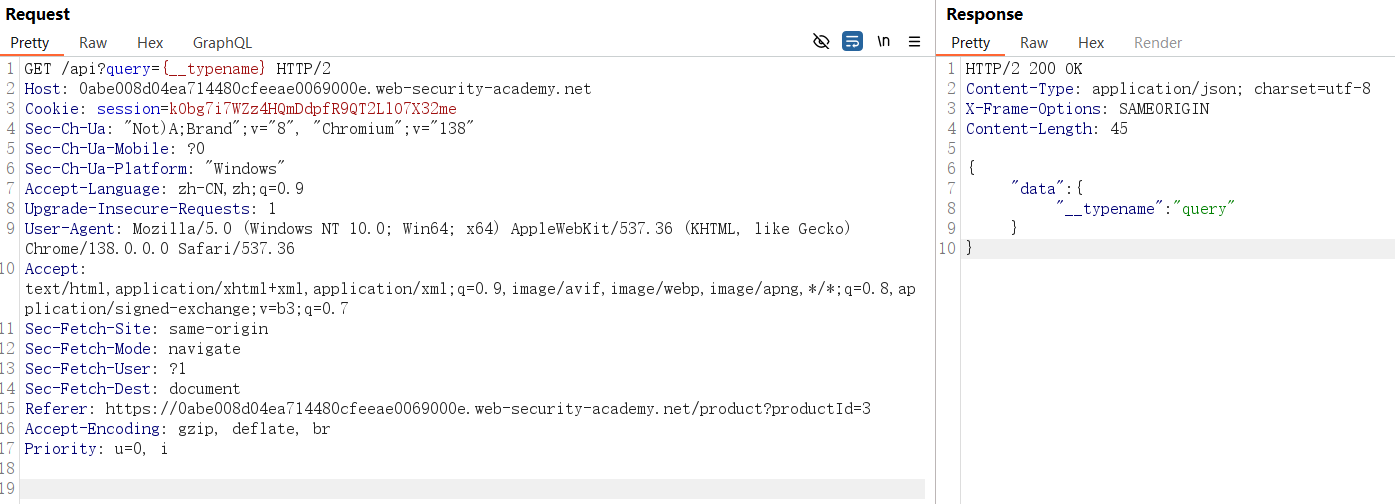
若 POST 请求失败,可尝试GET 请求(部分服务支持 GET,将查询作为query参数传递):
GET /graphql?query={__typename} HTTP/1.1
若返回包含data字段的 JSON 响应(如{"data": {"__typename": "Query"}}),则说明是有效的 GraphQL 端点。